Извлечение информации Texterra
Извлечение информации Texterra – это набор инструментов анализа текстов, позволяющий выявлять имена и прозвища сущностей (людей, мест, организаций и др.), искать их в базах знаний (Википедии), а также определять ключевые сущности.
В тот момент Владимиримя человека пытался побороть свою ярость.
После установления советской власти многие улицы Владимира![]() город Владимир были переименованы.
город Владимир были переименованы.
Вечный город![]() город Рим расположился на семи холмах более двух тысяч лет назад.
город Рим расположился на семи холмах более двух тысяч лет назад.
Возможные сценарии применения:
Поиск популярных медиаперсон в социальных сетях за последнее время
Поиск отзывов на продукцию (например, автомобили, фильмы) в Веб
Рекомендация сущностей, ассоциированных с заданной
Особенности:
Поддерживает более 30 типов сущностей
Может быть легко адаптировано для новых классов сущностей, благодаря применению машинного обучения
Следующее приложение демонстрирует возможности извлечения информации Texterra на примерах недавних новостных текстов и сообщений Twitter
На Харьковском направлении минометами уничтожили базу иностранных наемников. Как рассказал источник агентства в силовых структурах, боевики оборудовали склады и казармы в домах мирных жителей одной из деревень. Установить точное месторасположение базы удалось при помощи беспилотников, по выявленным координатам ударили из минометов.
Найденные сущности
Кроме того, на основе извлечения информации Texterra мы разработали несколько демо-приложений для конечных пользователей
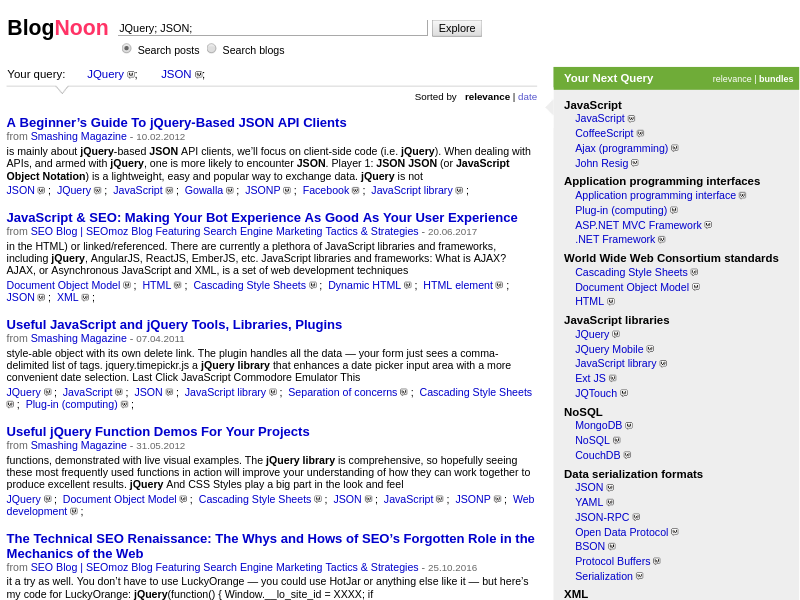
Анализ блогосферы
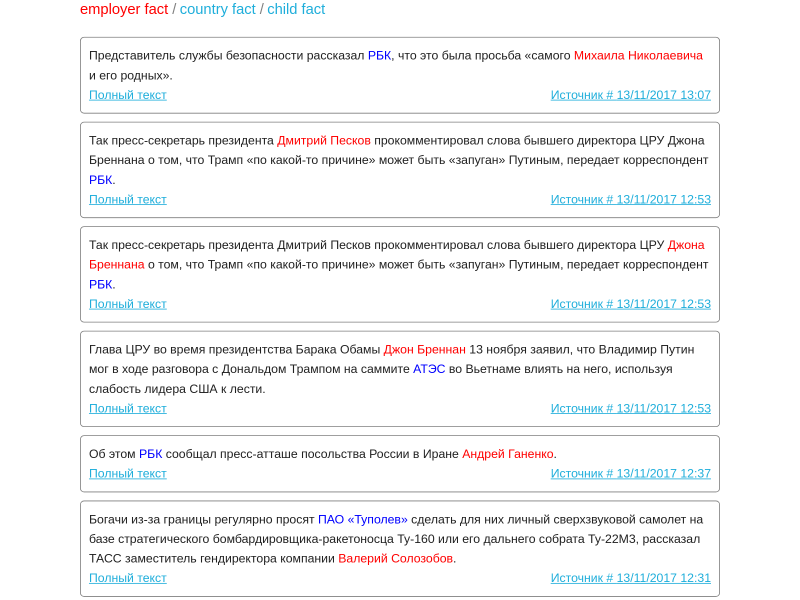
Извлечение фактов